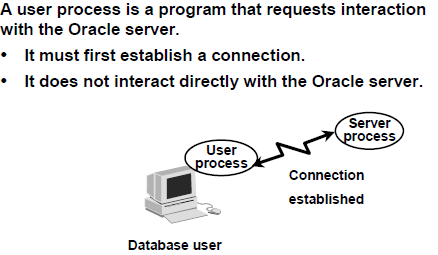
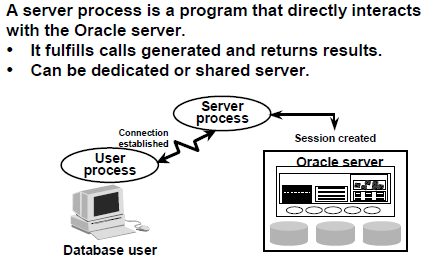
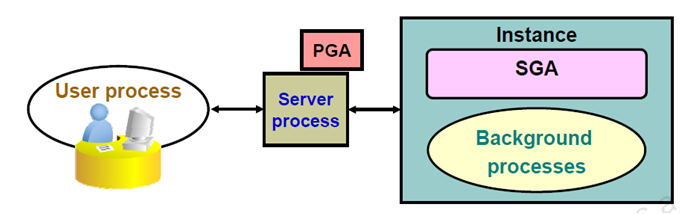
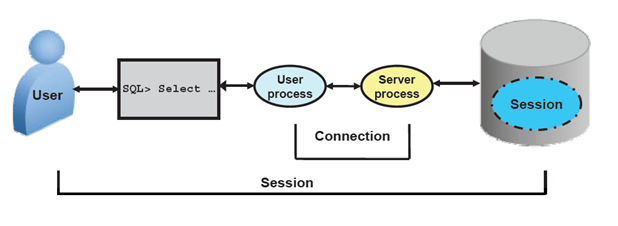
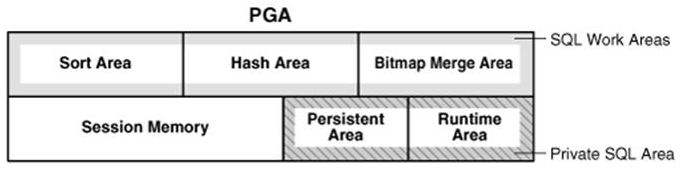
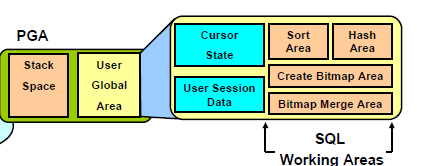
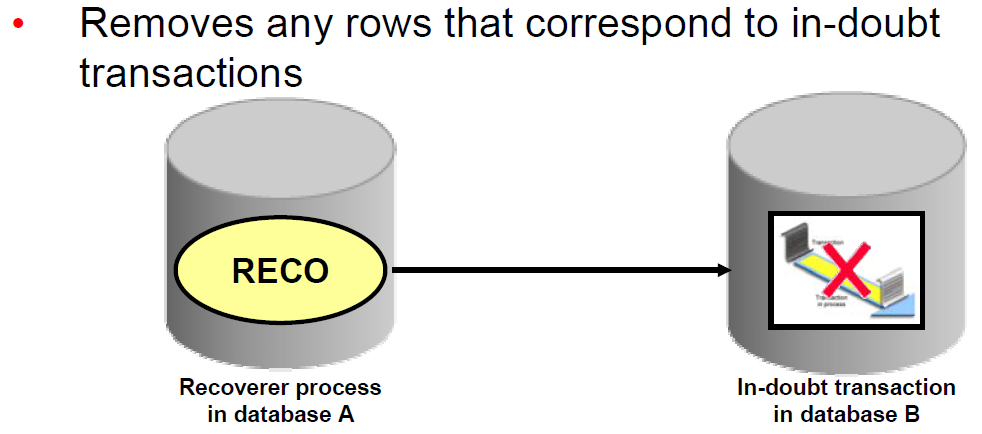
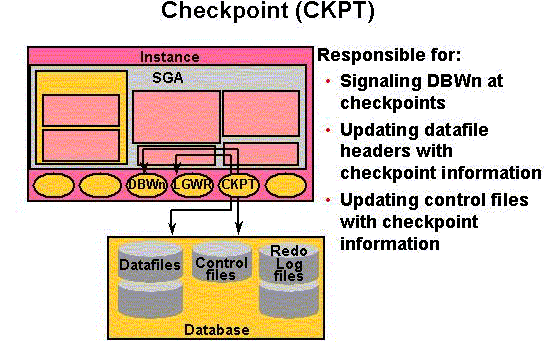
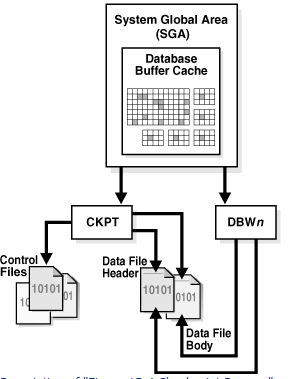
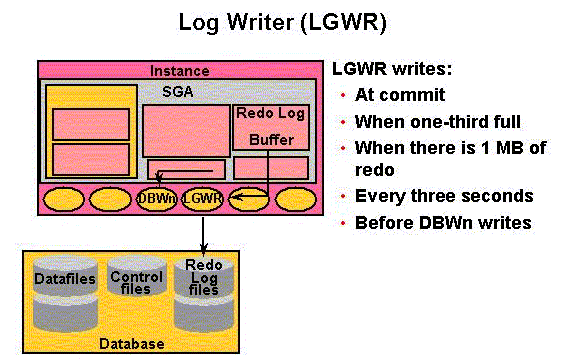
An Oracle database consists of files
 Datafiles:
Datafiles:
Every Oracle database has one or more physical datafiles, which contain all the database data. The data of logical database structures, such as tables and indexes, is physically stored in the datafiles allocated for a database.
At the operating system level, Oracle Database stores database data in structures called data files. Every Oracle database must have data file.
Tempfiles:
Tempfiles are used with TEMPORARY tablespaces and are used for storing temporary data like sort ,spill-over or data for global temporary tables.
Control Files:
Every Oracle Database has a control file, which is a small binary file that records the physical structure of the database. The control file includes: The database name. Names and locations of associated datafiles and redo log files.Every time an instance of an Oracle database is started, its control file identifies the datafiles, tempfiles, and redo log files that must be opened for database operation to proceed.
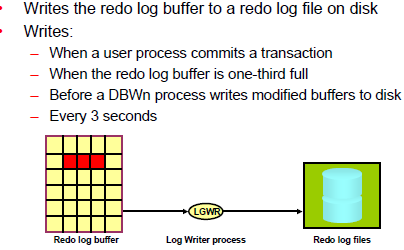
Redo Log Files :
The most crucial structure for recovery operations is the redo log, which consists of two or more pre-allocated files that store all changes made to the database as they occur. Every instance of an Oracle Database has an associated redo log to protect the database in case of an instance failure.
Redo log files contain a chronological record of changes made to the database, and enable recovery when failures occur.To protect against a failure involving the redo log itself, Oracle Database lets you create a multiplexed redo log so that two or more copies of the redo log can be maintained on different disks.
Archived Redo Log Files:
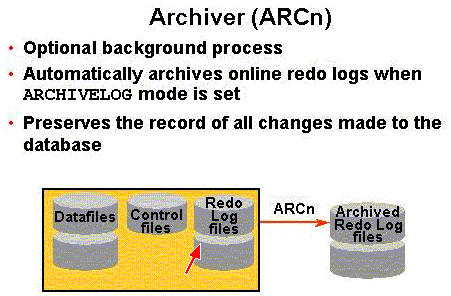
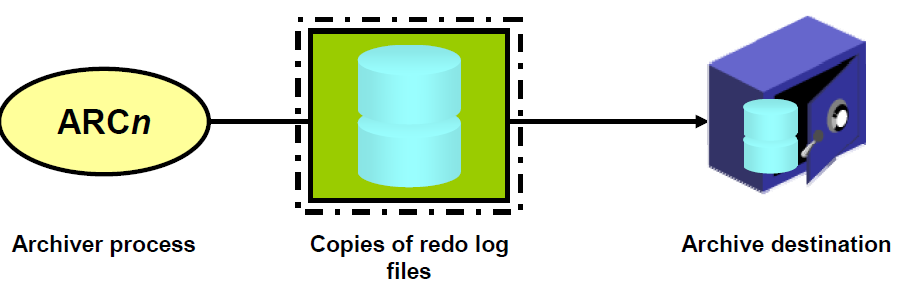
Archived redo log files are database-generated offline copies of online redo log files. Oracle Database automatically archives redo log files when the database is in ARCHIVELOG mode. Oracle recommends that you enable automatic archiving of the online redo log.Archive redo log files contain history of data changes (redo) that is generated by instance .
When the database is running in ARCHIVELOG mode, the log writer process (LGWR) cannot reuse and hence overwrite a redo log group until it has been archived.An archived redo log file is a copy of one of the filled members of a redo log group.
Parameter Files:
Parameter files contain a list of configuration parameters for that instance and database.There are two types of parameter files.
PFILE : The init.ora file (also called the PFILE) is a static parameter file. It contains parameters that specify how the database instance is to start up. For example, some parameters will specify how to allocate memory to the various parts of the system global area.
SPFILE : The spfile.ora is a dynamic parameter file. It also stores parameters to specify how to startup a database; however, its parameters can be modified while the database is running.
Password file : specifies which *special* users are authenticated to startup/shut down an Oracle Instance. its use to authenticate users over network.
Trace Log Files : Each server and background process can write to an associated trace file. When an internal error is detected by a process, the process dumps information about the error to its trace file. Some of the information written to a trace file is intended for the database administrator, while other information is for Oracle Support Services. Trace file information is also used to tune applications and instances.
Alert Files : The alert file, or alert log, is a special trace file. The alert log of a database is a chronological log of messages and errors.
Backup files :
To restore a file is to replace it with a backup file. Typically, you restore a file when a media failure or user error has damaged or deleted the original file.
User-managed backup and recovery requires you to actually restore backup files before you can perform a trial recovery of the backups.
Server-managed backup and recovery manages the backup process, such as scheduling of backups, as well as the recovery process, such as applying the correct backup file when recovery is needed.
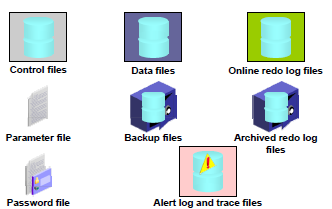
- Datafiles
- Temp files
- Control Files
- Online Redo Log Files
- Archived Redo Log Files
- Parameter Files
- Password Files
- Alert and Trace Log Files
- Backup Files
Every Oracle database has one or more physical datafiles, which contain all the database data. The data of logical database structures, such as tables and indexes, is physically stored in the datafiles allocated for a database.
At the operating system level, Oracle Database stores database data in structures called data files. Every Oracle database must have data file.
Tempfiles:
Tempfiles are used with TEMPORARY tablespaces and are used for storing temporary data like sort ,spill-over or data for global temporary tables.
Control Files:
Every Oracle Database has a control file, which is a small binary file that records the physical structure of the database. The control file includes: The database name. Names and locations of associated datafiles and redo log files.Every time an instance of an Oracle database is started, its control file identifies the datafiles, tempfiles, and redo log files that must be opened for database operation to proceed.
Redo Log Files :
The most crucial structure for recovery operations is the redo log, which consists of two or more pre-allocated files that store all changes made to the database as they occur. Every instance of an Oracle Database has an associated redo log to protect the database in case of an instance failure.
Redo log files contain a chronological record of changes made to the database, and enable recovery when failures occur.To protect against a failure involving the redo log itself, Oracle Database lets you create a multiplexed redo log so that two or more copies of the redo log can be maintained on different disks.
Archived Redo Log Files:
Archived redo log files are database-generated offline copies of online redo log files. Oracle Database automatically archives redo log files when the database is in ARCHIVELOG mode. Oracle recommends that you enable automatic archiving of the online redo log.Archive redo log files contain history of data changes (redo) that is generated by instance .
When the database is running in ARCHIVELOG mode, the log writer process (LGWR) cannot reuse and hence overwrite a redo log group until it has been archived.An archived redo log file is a copy of one of the filled members of a redo log group.
Parameter Files:
Parameter files contain a list of configuration parameters for that instance and database.There are two types of parameter files.
PFILE : The init.ora file (also called the PFILE) is a static parameter file. It contains parameters that specify how the database instance is to start up. For example, some parameters will specify how to allocate memory to the various parts of the system global area.
SPFILE : The spfile.ora is a dynamic parameter file. It also stores parameters to specify how to startup a database; however, its parameters can be modified while the database is running.
Password file : specifies which *special* users are authenticated to startup/shut down an Oracle Instance. its use to authenticate users over network.
Trace Log Files : Each server and background process can write to an associated trace file. When an internal error is detected by a process, the process dumps information about the error to its trace file. Some of the information written to a trace file is intended for the database administrator, while other information is for Oracle Support Services. Trace file information is also used to tune applications and instances.
Alert Files : The alert file, or alert log, is a special trace file. The alert log of a database is a chronological log of messages and errors.
Backup files :
To restore a file is to replace it with a backup file. Typically, you restore a file when a media failure or user error has damaged or deleted the original file.
User-managed backup and recovery requires you to actually restore backup files before you can perform a trial recovery of the backups.
Server-managed backup and recovery manages the backup process, such as scheduling of backups, as well as the recovery process, such as applying the correct backup file when recovery is needed.