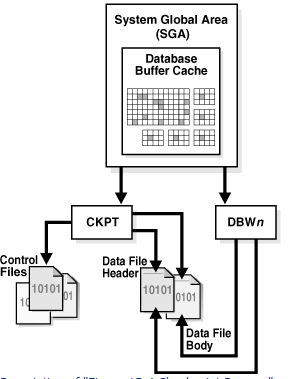
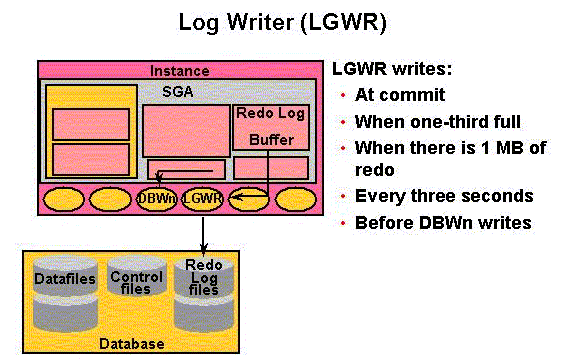
LGWR writes information from redo log buffers to redo log files .
Oracle database keeps record of changes made to data. Every time user performs a DML, DDL or DCL operation, its redo entries are also created. These redo entries contain commands to rebuild or redo the changes. These entries are stored in Redo Log buffer.
Log writer process (LGWR) writes these redo entries to redo log files. Redo log buffer works in circular fashion. It means that it overwrites old entries. But before overwriting, old entries must be copies to redo log files. Usually Log writer process (LGWR) is fast enough to mange these issues. Log writer process (LGWR) writes redo entries after certain amount of time to ensure that free space is available for new redo entries.
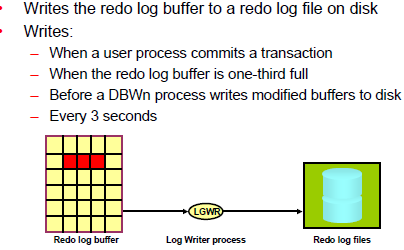
The Log Writer (LGWR) writes contents from the Redo Log Buffer to the Redo Log File that is in use. These are sequential writes since the Redo Log Files record database modifications based on the actual time that the modification takes place.
LGWR actually writes before the DBWn writes and only confirms that a COMMIT operation has succeeded when the Redo Log Buffer contents are successfully written to disk.
LGWR can also call the DBWn to write contents of the Database Buffer Cache to disk.
How LGWR works:
The redo log buffer is a circular buffer. When LGWR writes redo entries from the redo log
buffer to a redo log file, server processes can then copy new entries over the entries in the redo
log buffer that have been written to disk. LGWR normally writes fast enough to ensure that
space is always available in the buffer for new entries, even when access to the redo log is
heavy. LGWR writes one contiguous portion of the buffer to disk.
LGWR writes:
• When a user process commits a transaction
• When the redo log buffer is one-third full
• Before a DBWn process writes modified buffers to disk (if necessary)
• Every three seconds
Before DBWn can write a modified buffer, all redo records that are associated with the changes to the buffer must be written to disk (the write-ahead protocol). If DBWn finds that some redo records have not been written, it signals LGWR to write the redo records to disk and waits for LGWR to complete writing the redo log buffer before it can write out the data buffers. LGWR writes to the current log group. If one of the files in the group is damaged or unavailable, LGWR continues writing to other files in the group and logs an error in the LGWR trace file and in the system alert log. If all files in a group are damaged, or if the group is unavailable because it has not been archived, LGWR cannot continue to function.
When a user issues a COMMIT statement, LGWR puts a commit record in the redo log buffer and writes it to disk immediately, along with the transaction’s redo entries. The corresponding changes to data blocks are deferred until it is more efficient to write them. This is called a fast commit mechanism. The atomic write of the redo entry containing the transaction’s commit record is the single event that determines whether the transaction has committed. Oracle Database returns a success code to the committing transaction, although the data buffers have not yet been written to disk. If more buffer space is needed, LGWR sometimes writes redo log entries before a transaction is committed. These entries become permanent only if the transaction is later committed. When a user commits a transaction, the transaction is assigned a system change number (SCN), which Oracle Database records along with the transaction’s redo entries in the redo log. SCNs are recorded in the redo log so that recovery operations can be synchronized in Real Application Clusters and distributed databases.
In times of high activity, LGWR can write to the redo log file by using group commits. For example, suppose that a user commits a transaction. LGWR must write the transaction’s redo entries to disk. As this happens, other users issue COMMIT statements. However, LGWR cannot write to the redo log file to commit these transactions until it has completed its previous write operation. After the first transaction’s entries are written to the redo log file, the entire list of redo entries of waiting transactions (not yet committed) can be written to disk in one operation, requiring less I/O than do transaction entries handled individually. Therefore, Oracle Database minimizes disk I/O and maximizes performance of LGWR. If requests to commit continue at a high rate, every write (by LGWR) from the redo log buffer can contain multiple commit records