Instance and Media Recovery Structures

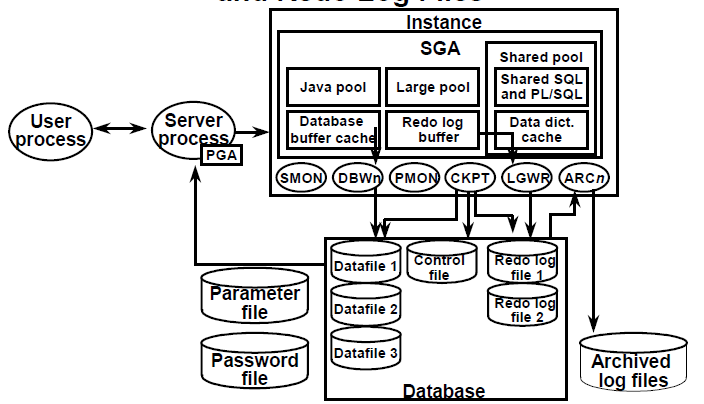
Oracle Instance
An Oracle instance consists of memory areas (mainly System Global Area [SGA]) and background processes, namely PMON, SMON, DBWn, LGWR, and CKPT. An instance is created during the nomount stage of the database startup after the parameter file has been read.If any of these processes terminate, the instance shuts down.
Memory Structures
Database buffer cache:
Memory area used to store blocks read from data files.Data is read into the blocks by server processes and written out by DBWn asynchronously.
Shared pool:
Stores parsed versions of SQL statements, PL/SQL procedures, and data dictionary information
Log buffer:
Memory containing before and after image copies of changed data to be written to the redo logs.
Large pool:
An optional area in the SGA that provides large memory allocations for backup and restore operations, I/O server processes, and session memory for the shared server and Oracle XA.
Background Processes
Database writer(DBWn):
Writes dirty buffers from the data buffer cache to the data files. This activity is asynchronous.
Log writer (LGWR):
Writes data from the redo log buffer to the redo log files
System monitor(SMON):
Performs automatic instance recovery. Recovers space in temporary segments when they are no longer in use. Merges contiguous areas of free space depending on parameters that are set.
Process monitor(PMON):
Cleans up the connection/server process dedicated to an abnormally terminated user process. Performs rollback and releases the resources held by the failed process.
Checkpoint (CKPT):
Synchronizes the headers of the data files and control files with the current redo log and checkpoint numbers.
Archiver (ARCn)(optional):
A process that automatically copies redo logs that have been marked for archiving.
The User Process:
The user process is created when a user starts a tool such as SQL*Plus, Oracle Forms Developer, Oracle Reports Developer, Oracle Enterprise Manager, and so on. This process might be on the client or server, and provides an interface for the user to enter commands that interact with the database.
The Server Process
The server process accepts commands from the user process and performs steps to complete user requests. If the database is not in a shared server configuration, a server process is created on the machine containing the instance when a valid connection is established.
Oracle Database
An Oracle database consists of the following physical files:
Datafiles(Binary):
Physical storage of data. At least one file is required per database. This file stores the system tablespace.
Redo logs file (Binary):
Contain before and after image copies of changed data, for recovery purposes. At least two groups are required
Control files(Binary):
Record the status of the database, physical structure, and RMAN meta data
Parameter file (Text):
Store parameters required for instance startup
Server parameter file(Binary):
Store persistent parameters required for instance startup
Password file(optional)(Binary):
Store information on users who can start, stop, and recover the database
Archive logs(optional)(Binary):
Physical copies of the online redo log files.Created when the database is set in Archivelog mode. Used in recovery.
Large Pool
The large pool is used to allocate sequential I/O buffers from shared memory. For I/O slaves and Oracle backup and restore.
Recovery Manager (RMAN) uses the large pool for backup and restore when you set the DBWR_IO_SLAVES or BACKUP_TAPE_IO_SLAVES parameters to simulate asynchronous I/O.
Sizing the Large Pool:
If LARGE_POOL_SIZE is set, then Oracle attempts to get memory from the large pool
If the LARGE_POOL_SIZE initialization parameter is not set, then the Oracle server attempts to allocate shared memory buffers from the shared pool in the SGA.
DBWR_IO_SLAVES: This parameter specifies the number of I/O slaves used by the DBWn process. The DBWn process and its slaves always write to disk. By default, the value is 0 and I/O slaves are not used.
BACKUP_TAPE_IO_SLAVES: It specifies whether I/O slaves are used by the Recovery Manager to backup, copy, or restore data to tape
To determine how the large pool is being used, query V$SGASTAT
Database Buffer Cache, DBWn and Datafiles:

Function of the Database Buffer Cache:
The database buffer cache is an area in the SGA that is used to store the most recently used data blocks.
The server process reads tables, indexes, and rollback segments from the data files into the buffer cache where it makes changes to data blocks when required.
The Oracle server uses a least recently used (LRU) algorithm to determine which buffers can be overwritten to accommodate new blocks in the buffer cache.
Function of the DBWn Background Process:
The database writer process (DBWn) writes the dirty buffers from the database buffer cache to the data files. It ensures that sufficient numbers of free buffers— buffers that can be overwritten when server processes need to read in blocks from the data files—are available in the database buffer cache.
The database writer regularly synchronizes the database buffer cache and the data files, this is the checkpoint event triggered in various situations
Although one database writer process is adequate for most systems, you can configure additional processes to improve write performance if your system modifies data heavily
Data Files
Data files store both system and user data on a disk. This data may be committed or uncommitted
Data Files Containing Only Committed Data:
This is normal for a closed database, except when failure has occurred or the "shutdown abort" option has been used. If the instance is shutdown using the normal, immediate or transactional option, the data files contain only committed data. This is because all uncommitted data is rolled back, and a checkpoint is issued to force all committed data to a disk.
Data Files Containing Uncommitted Data:
While an instance is started, datafiles can contain uncommitted data. This happens when data has been changed but not committed (the changed data is now in the cache), and more space is needed in the cache, forcing the uncommitted data off to disk. Only when all users eventually commit will the data files contain only committed data. In the event of failure, during subsequent recovery, the redo logs and rollback segments are used to synchronize the datafiles.
Configuring Tablespaces:
Tablespaces contain one or more datafiles. It is important that tablespaces are created carefully to provide a flexible and manageable backup and recovery strategy
System: Backup and recovery is more flexible if system and user data is contained in different tablespaces.
Temporary: If the tablespace containing temporary segments (used in sort, and so on) is lost, it can be re-created, rather than recovered.
Undo: The procedures for backing up undo tablespaces are exactly the same as for backing up any other read/write tablespace. Because the automatic undo tablespace is so important for recovery and for read consistency, you should back it up frequently.
Read-only data: Backup time can be reduced because a tablespace must be backed up only when the tablespace is made read-only.
Highly volatile data: This tablespace should be backed up more frequently, also reducing recovery time.
Index data: Tablespaces to store only index segments should be created. These tablespaces can often be re-created instead of recovered.
Redo Log Buffer, LGWR and Redo Log Files:
Function of the Redo Log Buffer
The redo log buffer is a circular buffer that holds information about changes made to the database. This information is stored in redo entries.
Redo entries contain the information necessary to reconstruct, or redo, changes made to the database by INSERT, UPDATE, DELETE, CREATE, ALTER, or DROP operations. Redo entries are used for database recovery, if necessary.
Redo entries are copied by Oracle server processes from the user’s memory space to the redo log buffer.
Function of the LGWR Background Process
The log writer (LGWR) writes redo entries from the redo log buffer to the redo log files as follows:
- When the redo log buffer is one-third full
- When a timeout occurs (every three seconds)
- When there is 1 MB of redo
- Before DBWn writes modified blocks in the database buffer cache to the data files
- When a transaction commits
Redo Log Files:
Redo log files store all changes made to the database. If the database is to be recovered to a point in time when it was operational, redo logs are used to ensure that all committed transactions are committed to disk, and all uncommitted transactions are rolled back. The important points relating to redo log files are as follows:
LGWR writes to redo log files in a circular fashion. This behavior results in all members of a log file group being overwritten.
Although it is mandatory to have at least two log groups to support the cyclic nature, in most cases, you would need more than two redo log groups.
Redo Log Switches
- At a log switch, the current redo log group is assigned a log sequence number that identifies the
- information stored in that redo log group and is also used for synchronization.
- log switch occurs when LGWR stops writing to one redo log group and begins writing to another.
- log switch occurs when LGWR has filled one log file group.
- DBA can force a log switch by using the ALTER SYSTEM SWITCH LOGFILE command.
- Checkpoint occurs automatically at a log switch.
Database checkpoints ensure that all modified database buffers are written to the database files.
The database header files are then marked current, and the checkpoint sequence number is recorded in the control file. Checkpoints synchronize the buffer cache by writing all buffers to disk whose corresponding redo entries were part of the log file being checkpointed.
Checkpoint Process (CKPT) Features
- The CKPT process is always enabled.
- The CKPT process updates file headers at checkpoint completion.
- More frequent checkpoints reduce the time needed for recovering from instance failure at the possible expense of performance.
Synchronization
- At each checkpoint, the checkpoint number is updated in every database file header and in the control file.
- The checkpoint number acts as a synchronization marker for redo, control, and data files. If they have the same checkpoint number, the database is considered to be in a consistent state.
- Information in the control file is used to confirm that all files are at the same checkpoint number during database startup. Any inconsistency between the checkpoint numbers in the various file headers results in a failure, and the database cannot be opened. Recovery is required.
