Whole database backup:
The whole backup that is taken when the database is closed (after the database is shut down using the NORMAL, IMMEDIATE, or TRANSACTIONAL options) is called a consistent backup. In such a backup, all the database file headers are consistent with the control file, and when restored completely, the database can be opened without any recovery. When the database is operated in Noarchivelog mode, only a consistent whole database backup is valid for restore and recovery.
When the database is open and operational, the datafile headers are not consistent with the control file unless the database is open in read-only mode. When the database is shut down with the ABORT option this inconsistency persists. Backups of the database in such a state are termed as an inconsistent backup. Inconsistent backups need recovery to bring the database into a consistent state. When databases need to be available 7 days a week, 24 hours a day, you have no option but to use an inconsistent backup, and this can be performed only on databases running in Archivelog mode.
Tablespace Backup:
A tablespace backup is a backup of the datafiles that make up a tablespace. Tablespace backups are valid only if the database is in Archivelog mode because redo entries will be required to make the datafiles consistent with the rest of the database. You can make tablespace backups when the tablespace is read-only or offline-normal in Noarchivelog mode.
Datafile Backups:
You can make backups of a single datafile if your database is in Archivelog mode.
Control File Backups:
You can configure RMAN for automatic backups of the control file after a BACKUP or COPY command is issued. The control file can also be backed up through SQL commands.
User-Managed Backup and Recovery
User-managed backup and recovery does not use Recovery Manager. Operating system commands are used to make backups of the database files and to restore them in a recovery situation. The recovery commands are issued in a SQL*Plus session.
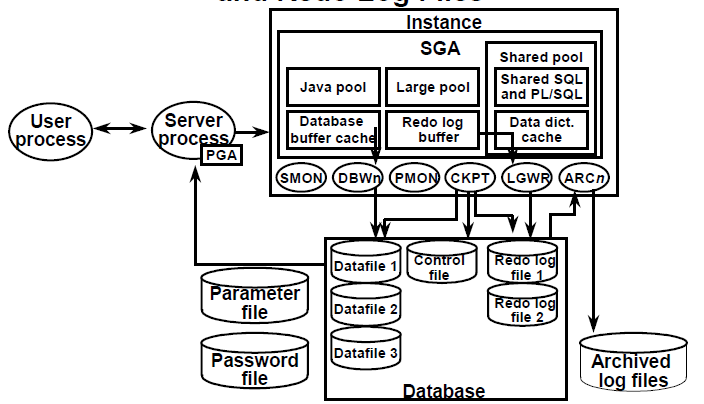
Querying Views to Obtain Database File Information:
Obtain information about the files of the database by querying the V$DATAFILE, V$CONTROLFILE, V$LOGFILE, and V$TABLESPACE views
Backup Method:
A user-managed database backup is an operating system backup of database files while the database is open or closed.
Physical Backup Methods
Operating system backup without archiving is used to recover to the point of the last backup after a media failure.
Operating system backup with archiving is used to recover to the point of failure after a media failure
Consistent Whole Database Backup
A consistent whole database backup, also known as a closed database backup, is a backup that is taken of all the datafiles and control files that constitute an Oracle database while the database is closed. It can also include the online redo log files, parameter file, and the password file.Ensure that the complete pathnames of the files are noted and used appropriately in the backup.
* It is not necessary to include the online redo log files as part of a whole database backup, if the database has been shut down cleanly, by using a normal, transactional, or immediate option. However, in cases where it is necessary to restore the entire database, the process is simplified if they have been backed up.
Advantages of Making Consistent Whole Database Backups:
A consistent whole database backup is conceptually simple because all you need to do is:
– Shut down the database
– Copy all required files to the backup location
– Open the database
Disadvantages of Making Consistent Whole Database Backups:
- For business operations where the database must be continuously available, a consistent whole database backup is unacceptable because the database is shutdown and unavailable during the backup
- The amount of time that the database is unavailable is affected by the size of the database,the number of datafiles, and the speed with which the copy operations on the data files can be performed. If this amount of time exceeds the allowable down time, you must choose another type of backup.
- The recovery point is only to the last full consistent whole database backup, and lost transactions may have to be entered manually following a recovery operation
Performing a Consistent Whole Database Backup:
Perform a consistent whole database backup while the Oracle server instance is shut down.
1. Compile an up-to-date listing of all relevant files to back up.
2. Shut down the Oracle instance with the SHUTDOWN NORMAL, SHUTDOWN IMMEDIATE, or SHUTDOWN TRANSACTIONAL command.
3. Back up all datafiles and control files by using an operating system backup utility. You can also include the redo log files although it is not required. You should also backup the parameter file and the password file
4. Restart the Oracle instance.